時間:2024-03-12 13:41:23來源:處芯積律
近期的全國政協會議也談到了這個---“人工智能已經成為國家間科技競爭的必爭之地。要深入挖掘國產AI芯片算力潛力,加速推動國產操作系統發展,夯實人工智能發展算力底座,助推新質生產力跑出加速度”。所以我們談下AI芯片。
作為專為AI計算需求而設計制造的集成電路,AI芯片不僅革新了計算機處理信息的方式,更在圖像識別、語音識別、自然語言處理、自動駕駛等多個前沿領域發揮了至關重要的作用。
AI芯片的基本概念
AI芯片,也稱作AI加速器或智能芯片,是一種特制的微處理器,專門為高效運行人工智能算法而設計。不同于傳統的CPU、GPU等通用處理器,AI芯片致力于解決AI應用中的大規模并行計算問題,尤其是針對神經網絡模型的密集型數學運算,如矩陣乘法、卷積操作和激活函數計算等。這種高度定制化的設計極大地提升了計算效率,降低了能耗,并實現了實時響應和高性能推理能力。
AI芯片的技術原理與架構
人工神經網絡模型 AI芯片的核心原理基于人工神經網絡,其中芯片內部的處理單元模擬了生物神經元的工作機制。每一個處理單元能夠獨立進行復雜的數學運算,例如權重乘以輸入信號并累加,形成神經元的激活輸出。激活函數則決定了信號如何轉化為有意義的結果,它是AI芯片中不可或缺的一部分。
硬件架構 AI芯片的硬件架構多種多樣,根據其設計目標和應用場景,可分為以下幾類:
GPU(圖形處理器): GPU原本主要用于圖形渲染,但因其并行計算能力強,被廣泛用于訓練大型深度學習模型,尤其擅長處理浮點數密集型計算任務。
FPGA(現場可編程門陣列): FPGA具有高度靈活的可編程性,能夠在硬件層面快速重新配置以適應不同的AI算法,適用于早期開發階段和動態工作負載的場景。
ASIC(專用集成電路): ASIC是為特定AI任務定制的芯片,相較于GPU和FPGA,它在特定應用中的計算效率更高,能耗更低,但缺乏通用性。
TPU(張量處理單元): Google推出的TPU是專門針對機器學習任務設計的ASIC實例,專注于高效的矩陣運算,尤其適合TensorFlow框架下的深度學習模型。
AI芯片的分類與市場應用
AI芯片廣泛應用于各個領域,包括但不限于:
1、自動駕駛:AI芯片能夠實時處理車輛傳感器收集的數據,實現精確的導航和決策,提高自動駕駛的安全性和可靠性。
2、智能安防:AI芯片可用于視頻監控、人臉識別等安防領域,提高安全監控的效率和準確性。
3、智能家居:AI芯片能夠支持智能家居設備的智能化控制和管理,提升居住體驗。
4、醫療健康:AI芯片可用于醫療影像分析、疾病診斷等領域,輔助醫生進行精準治療。
國內AI芯片現狀以及未來挑戰
國內AI芯片市場近年來發展迅猛,涌現出了一批具有創新能力和市場競爭力的企業,其中一些知名的包括華為、寒武紀、地平線、百度等,國外有英偉達等,下面分別列舉了每個公司的一款芯片的介紹:
華為海思的昇騰910
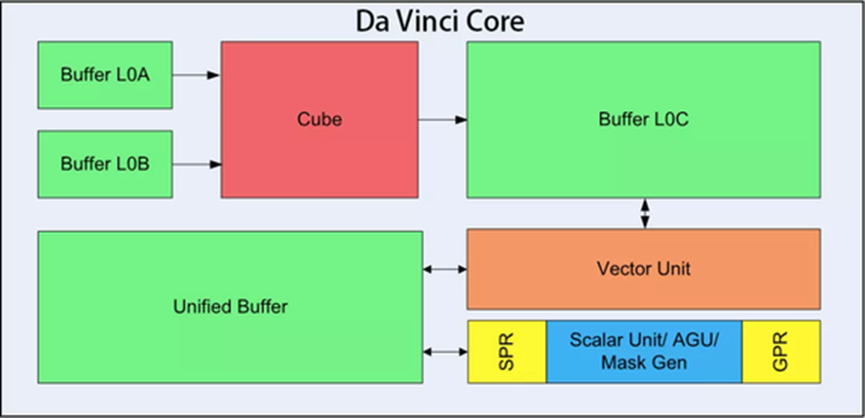
達芬奇架構
架構:基于達芬奇架構設計
制程工藝:7nm
核心數量:配備有大量AICore(人工智能內核),例如提到的256個AICore
性能指標:半精度(FP16)算力:高達256TeraFLOPS(每秒萬億次浮點運算)
整數精度(INT8)算力:可達512 TeraOPS(每秒萬億次整數運算)
支持高速內存接口和通道,比如128通道全高清視頻編解碼能力
最大功耗:約為350瓦
寒武紀的思元370
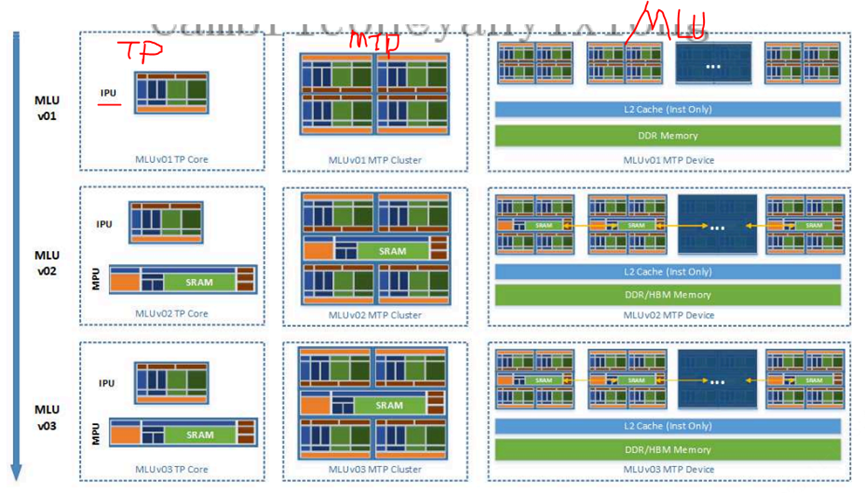
MLU架構
架構:MLUarch03
算力:最高256 TOPS(INT8),64 TOPS(FP16)
制程工藝:7nm
性能指標:最大算力高達256TOPS(INT8精度)
集成的晶體管數量:390億個
內存支持:支持LPDDR5內存
應用場景:適用于云計算數據中心
最大功耗: 250W
地平線的征程5
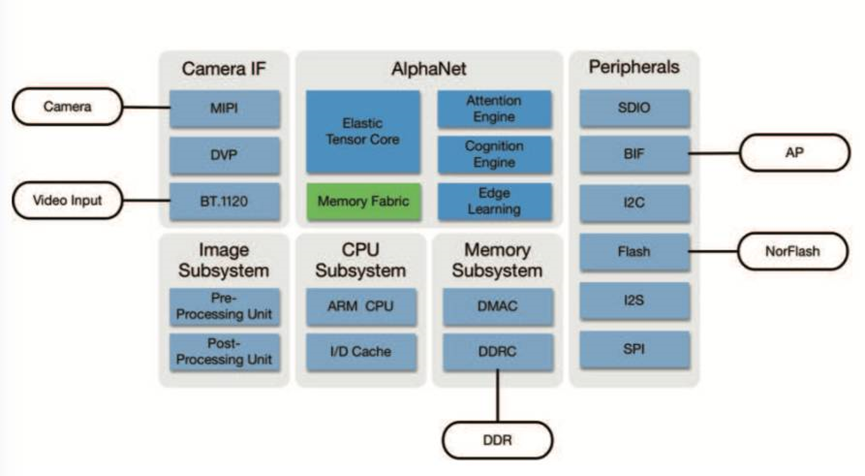
地平線架構
征程5:
架構:雙核BPU:地平線自研的第二代貝葉斯架構,專為AI計算優化。
算力:單顆芯片AI算力最高可達128TOPS,能夠處理大量的并行計算任務。
功耗:30W
工藝:16nm
應用場景:自動駕駛、智能座艙、智能監控等車載AI
百度昆侖芯片
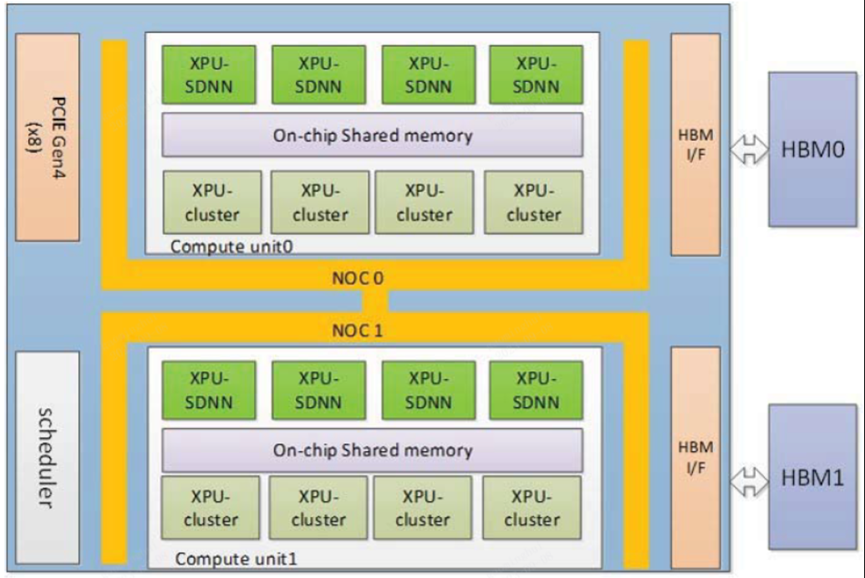
昆侖架構
架構:百度昆侖2芯片采用自研的第二代XPU架構,這是一種針對AI計算進行了深度優化的架構設計,能夠高效執行大規模并行計算任務,特別適合深度學習和機器學習算法的處理。
算力:INT8整數精度算力達到256TeraOPS(每秒萬億次整數運算)。
半精度(FP16)算力為128 TeraFLOPS(每秒萬億次浮點運算)。
功耗:最大120W
工藝: 7nm。
應用場景:百度昆侖2芯片適用于云、端、邊等多場景的AI計算需求。
英偉達H100
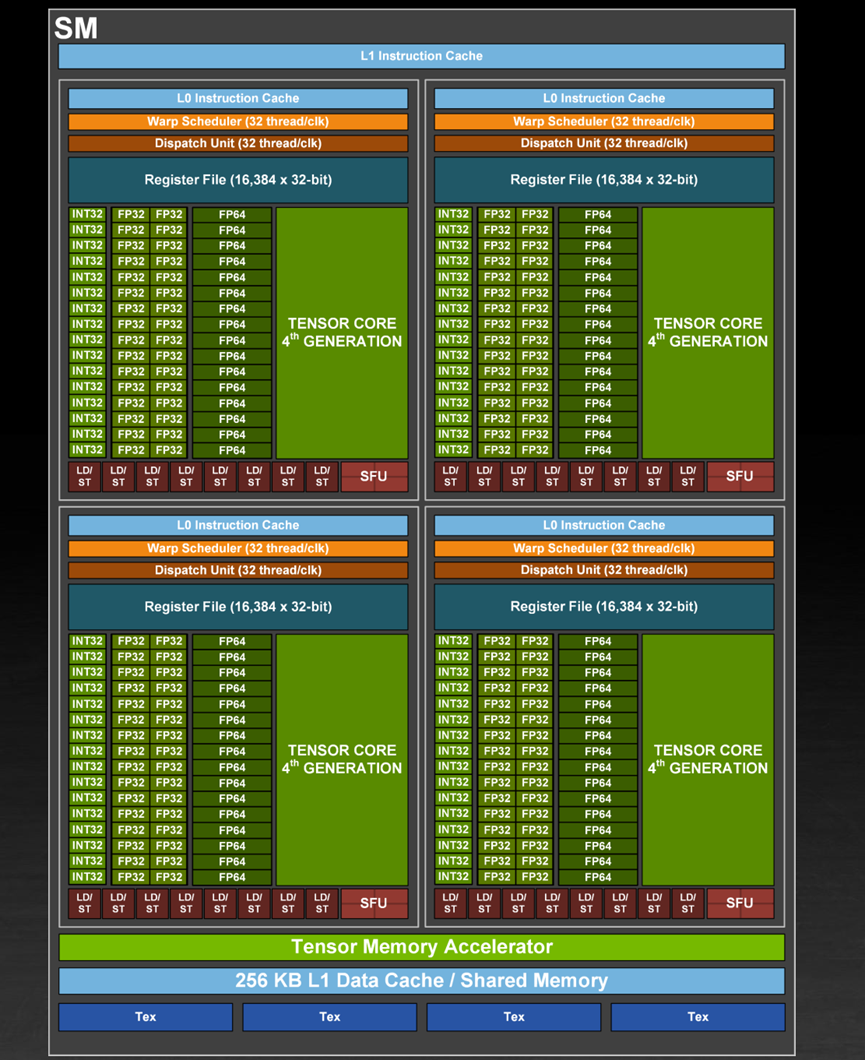
Nvidia H100SM
架構:Hopper架構
算力:FP64為67TFLOPS;
FP32為989TFLOPS;
FP16為1979TFLOPS;
BF16為1979TFLOPS;
INT8為3958TFLOPS
功耗:700W
工藝:4nm
應用場景:機器學習、深度學習訓練和推理、科學計算模擬、數據分析、自然語言處理等
可以看出,盡管國內AI芯片在設計和應用上取得了一定的成就,但與英偉達等國際領先企業相比,仍存在一定的性能差距。國內AI芯片還面臨著一系列關鍵的挑戰:
1、技術壁壘與核心專利:在高端芯片設計、EDA工具、IP核以及先進制造工藝等方面,我國企業與國際領先水平相比存在差距,尤其是在7nm及以下的先進制程上,對外國先進技術和設備的依賴度較高,還面臨被制裁的風險。
2、市場競爭與品牌認知:雖然國內市場華為等廠商影響力較大,但在國際市場上,英偉達、英特爾、AMD等公司在AI芯片領域還是占據了主導地位,中國企業要在全球范圍內建立品牌影響力和客戶信任度尚需時日。
3、人才儲備與培養:高端AI芯片研發和設計需要大量專業人才,涉及的專業技術覆蓋廣泛,包括集成電路設計、算法優化、材料科學等,而中國在人才培養和引進方面還需進一步加強,以支撐產業的長遠發展。
隨著國內企業的不斷努力和創新,相信未來這一差距會逐漸縮小。同時,國家也應加大對AI芯片產業的支持力度,推動國內AI芯片產業的快速發展。
中國傳動網版權與免責聲明:凡本網注明[來源:中國傳動網]的所有文字、圖片、音視和視頻文件,版權均為中國傳動網(www.hysjfh.com)獨家所有。如需轉載請與0755-82949061聯系。任何媒體、網站或個人轉載使用時須注明來源“中國傳動網”,違反者本網將追究其法律責任。
本網轉載并注明其他來源的稿件,均來自互聯網或業內投稿人士,版權屬于原版權人。轉載請保留稿件來源及作者,禁止擅自篡改,違者自負版權法律責任。
產品新聞
更多>
2025-06-16

2025-06-09

2025-06-06

2025-05-19

2025-04-30

2025-04-11












 網站客服
網站客服 粵公網安備 44030402000946號
粵公網安備 44030402000946號